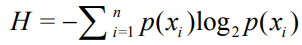1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
| from collections import defaultdict
import copy
from math import log
def createDataSet():
dataset = [
[1,1,'y'],
[1,1,'y'],
[1,0,'n'],
[0,1,'n'],
[0,1,'n'],
]
label = ['鬼畜摇摆,一秒内来回走位十几次?','百分百走位躲技能?']
return dataset,label
dataset,label = createDataSet()
def calcShannonEnt(dataset):
'''
计算数据的熵
这里计算的是最后一列的熵 也就是label那一列
'''
l = len(dataset)
d = defaultdict(int)
for i in dataset:
d[i[-1]]+=1
sn = 0
for i in d.values():
prop = i/l
sn-=prop*log(prop,2)
return sn
def splitDataSet(dataSet,axis,value):
'''
划分数据集
'''
dtst = copy.deepcopy(dataSet)
retDataSet=[]
for i in dtst:
if i[axis]==value:
i.pop(axis)
retDataSet.append(i)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
'''
找出最好的划分方式
'''
numFeatures = len(dataSet[0])-1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0;bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet) / len(dataset)
newEntropy+=prob*calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if(infoGain>bestInfoGain):
bestInfoGain = infoGain
bestFeature=i
return bestFeature
def majorityCnt(classList):
classCount = defaultdict(int)
for vote in classList:
classCount[vote]+=1
sortedClassCount = sorted(classCount.items(),key = lambda x:x[1],reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0])==1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree={bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels=labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree
T = createTree(dataset,label)
def classify(inputTree,featLabels,testVec):
firstStr = list(inputTree.keys())[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex]==key:
if type(secondDict[key]).__name__=='dict':
classLabel = classify(secondDict[key],featLabels,testVec)
else:classLabel = secondDict[key]
return classLabel
print(classify(T,['鬼畜摇摆,一秒内来回走位十几次?','百分百走位躲技能?'],[1,1]))
|